Open banking is a global technological and political movement that enables customers to share their financial data—previously siloed in their financial institutions—to 3rd party organizations. Done through API, this has allowed consumers to enjoy more customized products and diverse services built on top of their shared data. Furthermore, consumers who were unhappy with their existing service providers now can walk away anytime and easily transfer their data to another institution. At the same time, it has enabled various new providers to enter the fray by drastically reducing the barrier to access data.
Similar to open banking, we need to open up gig drivers’ data and empower drivers to take control of their records.
The Gig Economy is here to stay and working as an independent contractor will be an even bigger part of modern labor, as addressed by California’s AB5. As the name “independent” suggests, independent contractors should be able to “keep” and control their working data. When we say we have worked for a company we maintain our own mental and personal record of the work and achievements at our employers in the form of a resume, even though the work itself remains at the company as their asset. This is not an ideal way of showcasing or proving one’s experience, but because much of our work is qualitative and idiosyncratic, this will have to do. However as we already know, our most prominent independent gigs—driving and delivering—are almost completely quantifiable and identical across platforms.
Hundreds, if not thousands, of platforms exist that leverage independent drivers and couriers. Uber, Lyft, Doordash, GoPuff, Rappi, Foodpanda, Instacart, and Getir just to name the biggest players. Belying the number of numerous platforms, Driver Partners’ (which platforms usually like to address them as) work is largely uniform.
(1)They take the order → (2) Arrive by pick-up point to take a passenger or food → (3) Move → (4) Drop-off → (5) Finish
Most journeys have the same 5 step cycle with every delivery or ride following the same pattern. This likely also results in highly similar datasets and data points pertaining to the deliveries or rides such as when the driver arrived, how long they waited, and how long they took. Unfortunately, these similar datasets currently sit siloed with each platform. And precisely because of their independent contractor status allowing them to work across multiple platforms, their data is ironically even more fragmented. If we go back to our resume reference, this is akin to working for a company, but having no objective way to prove it (Only your gas bill will be there to attest). This is net negative for everyone involved – including the platforms.
Let’s first look at drivers. Siloed data, while largely identical, makes it extremely hard and tedious for drivers to prove their quality and work ethics when they move or apply to work for other platforms. In Foodpanda, for instance, when you first join, you are assigned to Tier 6. You can sign up in shifts after all tiers ( 1 – 5) had the chance to sign up. And then you are forced to prove that you are a “good” driver by not rejecting assigned orders. Such hierarchy allows platforms to effectively handle undesirable orders at lower cost and further compress gig drivers’ income. From society as a whole, if you are a 5 star courier for DoorDash, you at least shouldn’t start from the bottom of the chain in Foodpanda because you’ve already proven your capability elsewhere. What should rightfully happen, similar to our credit scores, is our rides accumulating with us, and not just with the platforms.

When couriers can come bundled with their records, this is also net positive to platforms as well. One of the key jobs of any platform is to manage driver lifecycle efficiently by effectively acquiring and retaining good drivers and weeding out the bad ones quickly. If drivers come armed with their own data, this not only simplifies the process, but also, greatly improves it by giving troves of data for them to work with. (And perhaps different platforms will find different ways to evaluate drivers like how underwriting is evolving). Platforms can now focus on recruiting, retaining, and training quality drivers, who will not only boast higher productivity, but also drive higher customer satisfaction. At the same time, they will be able to dramatically reduce their spending on fending off or compensating for bad drivers. No waste appears across both ends. As a result, diligent and good drivers will enjoy better pay and platforms will be able to increase driver productivity. And of course, as a consumer, you are more likely to encounter good drivers. Especially in ultra competitive places like Hong Kong where you have more than 7+ players competing for drivers, driver data will give everyone more to work with, not less.
Thankfully it seems like we’re slowly moving towards freer courier data. Uber (while now publicly inaccessible) offers API that share driver’s ride data. As you can see below, they offer very granular insight to drivers. Just look at the status changes and their corresponding timestamps. You can do all kinds of analyses with the data here, starting from very simple things like how many rides the driver has completed to on average how long it takes for the driver to arrive at the pick-up location to more subjective ones like how efficient the driver is.
{
"count": 1200,
"limit": 1,
"trips": [
{
"fare": 6.2,
"dropoff": {
"timestamp": 1502844378
},
"vehicle_id": "0082b54a-6a5e-4f6b-b999-b0649f286381",
"distance": 0.37,
"start_city": {
"latitude": 38.3498,
"display_name": "Charleston, WV",
"longitude": -81.6326
},
"status_changes": [
{
"status": "accepted",
"timestamp": 1502843899
},
{
"status": "driver_arrived",
"timestamp": 1502843900
},
{
"status": "trip_began",
"timestamp": 1502843903
},
{
"status": "completed",
"timestamp": 1502844378
}
],
"surge_multiplier": 1,
"pickup": {
"timestamp": 1502843903
},
"driver_id": "8LvWuRAq2511gmr8EMkovekFNa2848lyMaQevIto-aXmnK9oKNRtfTxYLgPq9OSt8EzAu5pDB7XiaQIrcp-zXgOA5EyK4h00U6D1o7aZpXIQah--U77Eh7LEBiksj2rahB==",
"status": "completed",
"duration": 475,
"trip_id": "b5613b6a-fe74-4704-a637-50f8d51a8bb1",
"currency_code": "USD"
}
],
"offset": 0
}Of course, some of the fields here, like exact locations and surge multiplier, are quite sensitive proprietary data. I actually think they should be hidden and, as an industry, we should set up industry standards that contain essential, but not mission critical information. I can easily see duration, status changes, distance, fare, and rating (which is not available here) becoming the backbone of each ride’s critical information.
Interestingly, Latin American fintech Belvo is already several steps ahead. They aim to be LATAM’s Plaid, but with a twist of offering gig workers’ data on top. As Belvo is pioneering, the trove of driver data is a huge asset for financial institutions because similar to credit card transactions that signify consumers’ spending, these delivery records signify drivers’ earning. With these data, firms can build extremely customized payday loans or products just for gig drivers such as insurances. (If I were Doordash or Foodpanda’s fintech team, a payday product would be the product to work on). And because driving is an earning activity, you can have the collection flow built-in. How beautiful!
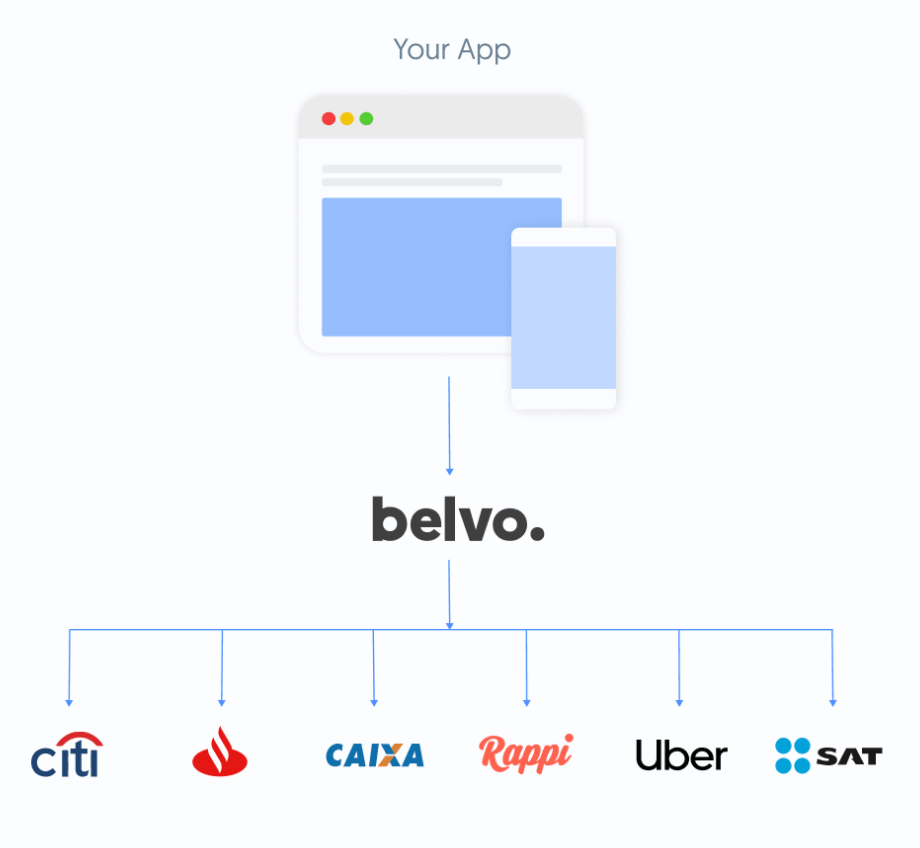
If I become a little bit more ambitious, we need a meta layer that manages HR and finance for gig drivers. It’s a platform where gig drivers can consolidate their experience, share their data to other ride sharing platforms, and subscribe to financial products provided by financial institutions. There should be a one stop solution that can mediate all these, but at the same time, also give drivers the freedom to move away to another meta platform if they choose to do so by supporting data exports. Perhaps we can start by creating an analytics tools for drivers to analyze their rides across platforms, so that they will voluntarily share their own data. In the future, DAO membership may be given to riders in exchange for their data. And as a platform you can open up the data to other delivery platforms through an API.
Most of our everyday services now rely on independent gig workers for some parts of their journey. I’ve shadowed multiple couriers and have fulfilled some orders myself. Every time, I’m amazed at how physically and mentally demanding their work is. It demands extensive local knowledge, streamlined SOPs, and stamina. For instance, if you are delivering to an apartment, you must know where to park, where the entrance is, what the SOP set by the janitors or apartment management is, and even use the correct cargo elevator. It’s not hard to imagine every building also having their slight variations. They are our unsung heroes and they deserve better. I hope that starts with them owning their own data. I hope that ABC test that California’s AB 5 put forward, can add a “D” clause that goes something like – The worker keeps their own work data, free from the control and direction of the hiring entity…

Thank my colleague Guillermo Medina for reading and editing the post 🙂

Leave a comment